




La República AdTech está
sumida en el caos. Los
identificadores de las rutas
publicitarias en los entornos
publisher y advertiser están en
disputa....
Si hiciéramos una parodia de la película Star Wars ambientándola en lo que estamos viviendo en la industria AdTech, seguramente veríamos en pantalla una galaxia donde caen unos rótulos como los que habéis leído. Después de la última estocada de Google confirmando sus intenciones de poner fecha de vencimiento las cookies de 3rd Party y otras causas que podéis leer en esta publicación, la industria AdTech está inmersa en una suerte de carrera o guerra para buscar soluciones alternativas o, como a veces parece, la solución definitiva que sustente el desarrollo futuro.
La preocupación y el murmullo del sector está muy presente ya que muchas voces ponen de manifiesto que se está tardando mucho en establecer soluciones claras y consistentes para el futuro del AdTech.

FUENTE: AdExchanger, Comic: Faster! Faster! by Nate Neal
Por eso motivo y de cara a poner algo de orden, este es el primer capítulo de una serie de publicaciones donde desgranaré -ya aviso que intentaré bajar al barro- las principales alternativas que se están poniendo encima del tablero para un mundo cookieless. Así en Madtech Soul hablaremos sobre Google Privacy Sandbox, SPARROW, Universal ID, Edge Computing, Walled Garden, etc.. Let's go!
Un ID para gobernarlos a todos…
Todo debe tener un inicio y yo he elegido empezar hablando del Universal ID, porque seguramente es del que más llevaréis tiempo escuchando hablar.
Debido a la forma en que los publishers y anunciantes confiaban en las cookies de terceros para obtener resultados, la publicidad dirigida podría parecer imposible sin éstas. Y es por eso que, empresas de soluciones de identidad como LiveRamp, Zeotap, Infosum o ID5 y, por otro lado, consorcios como IAB con el Proyecto Rearc o el Advertising ID Consortium, llevan tiempo trabajando en la creación de identificadores de usuario universales y compatibles con la finalidad de poder impactar a los usuarios incluso después de la eliminación de las cookies y también poder omitir el proceso de cookie syncing .
El Universal ID es un identificador creado con la finalidad de proporcionar una identidad compartida que identifique -valga la redundancia- al usuario en toda los puntos sin tener la necesidad de sincronizar cookies. Lo más habitual es que se utilice 1st Party Data (por ejemplo, del CRM) o datos offline (ejemplo el teléfono) para crear estos ID universales.
A diferencia de las cookies que se basan en coincidencias probabilísticas, los Universal ID, en su mayoría, se crean sobre la base de coincidencias deterministas.
Es importante comentar que el Universal ID no se debe confundir con otro tipo de procesos de identificación que llevan usándose mucho tiempo en la industria AdTech como son:
Los emails hasheados (HEM del inglés Hashed Email). En esta solución se utilizan distintas técnicas de hasheo -normalmente SHA256- para enmascarar o pseudo-anonimizar los emails de los usuarios, para después compartirlos con una plataforma de activación y convertir, así, ese hash en el identificador del cliente en los distintos puntos de contacto. Es decir, el hash de toni@toni.com coincidiría en nuestro CRM y en la plataforma de activación porque sería igual. Como ejemplos muy conocidos en este sentido, podéis encontrar Google Customer Match o Facebook Audience.
Identificadores de dispositivos móviles y Connected TV. En el entorno de las apps no tenemos cookies, ya que en su lugar se utilizan identificadores en función del sistema operativo del móvil. Aquí es necesario decir que también veremos restricciones ya que Apple ha anunciado que quiere bloquear el acceso a su identificador, el IDFA. Para el entorno del Connected TV y sus ID (CTV ID) el monte es todo orégano ya que todavía la regulación y las restricciones no han entrado con su maquinaria apisonadora.
Identificadores universales basados en cookies de 3rd Party. En este caso, uno muy conocido es The Trade Desk (aunque ha anunciado que está trabajando en una versión 2.0 que no trabaja con cookies de tercera parte).
¿Qué fue antes el huevo o la gallina?
No sé si deciros, en este caso, si el huevo o la gallina, pero sí que os puedo decir que el Universal ID nació antes de que los navegadores decidieran bloquear cookies y con el objetivo de corregir o mitigar algunos problemas derivados del modelo basado en los caducos identificadores de tercera parte.
Como siempre, con un ejemplo lo entendereis mejor. Supongamos que un publisher (un medio) se ha asociado con varios socios de tecnología publicitaria (por ejemplo, SSP, DMP, etc.). Cuando un usuario visita una de sus páginas web, cada uno de los socios de tecnología publicitaria con sus cookies (ID de cookies) debe sincronizarse entre sí para identificar al usuario. Especialmente, cuando el usuario es nuevo en esas plataformas, se debe crear una identificación de usuario única y luego sincronizarla entre sí, un proceso que ya hemos visto y que se llama cookie syncing.
Al no existir una identificación estandarizada que pueda funcionar para todos los involucrado en el proceso, esta sincronización de cookies ralentiza la carga de la página web y también reduce las tasas de éxito de la sincronización (match rate).
Es decir, el proceso de la sincronización de cookies no es perfecto y por el camino se pierden datos que hubieran supuesto una mayor identificación de una audiencia y, por lo tanto, la posibilidad de obtener un mejor ROI de una campaña.
Bajemos al barro
Para entrar en materia y ver cómo funciona exactamente el Universal ID y cuál el enfoque de cómo se adaptaría a los casos de uso normales del mundo AdTech, usaremos diagramas de algunas de las soluciones que tienen a bien hacerlos públicos. Si alguna solución lee la publicación y quiere aportar más detalle, será muy bien recibida por esta comunidad ansiosa de conocimiento.
Antes de entrar a detallar los casos de uso, vamos a ver las diferencias en la implementación con el modelo tradicional de cookies. Sobre este tema, ZEOTAP tiene un diagrama que lo especifica de forma clara comparándolo con el proceso actual que utiliza cookies de tercera parte.

FUENTE: ZEOTAP, ID+ zeotap.com
Así, vemos que la principal diferencia reside en que se recoge de forma hasheada un identificador determinista (en este ejemplo un email de una suscripción) para comparar si existe en el Universal ID o por el contrario se debe establecer uno nuevo para ese usuario.
Caso de uso de identificación
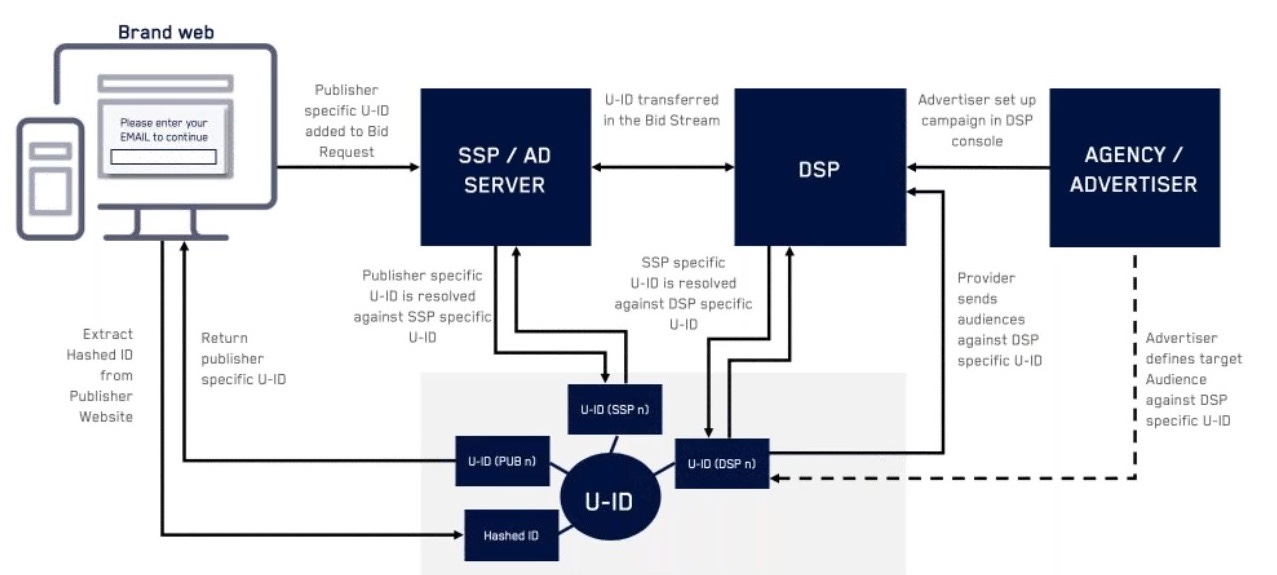
FUENTE: ZEOTAP, ID+ zeotap.com
Es interesante ver como cada actor tiene un ID que permite identificar al usuario en todos los puntos del proceso, sin embargo la identidad completa está sólo en un único punto (en el ejemplo en U-ID).
Caso de uso de medición
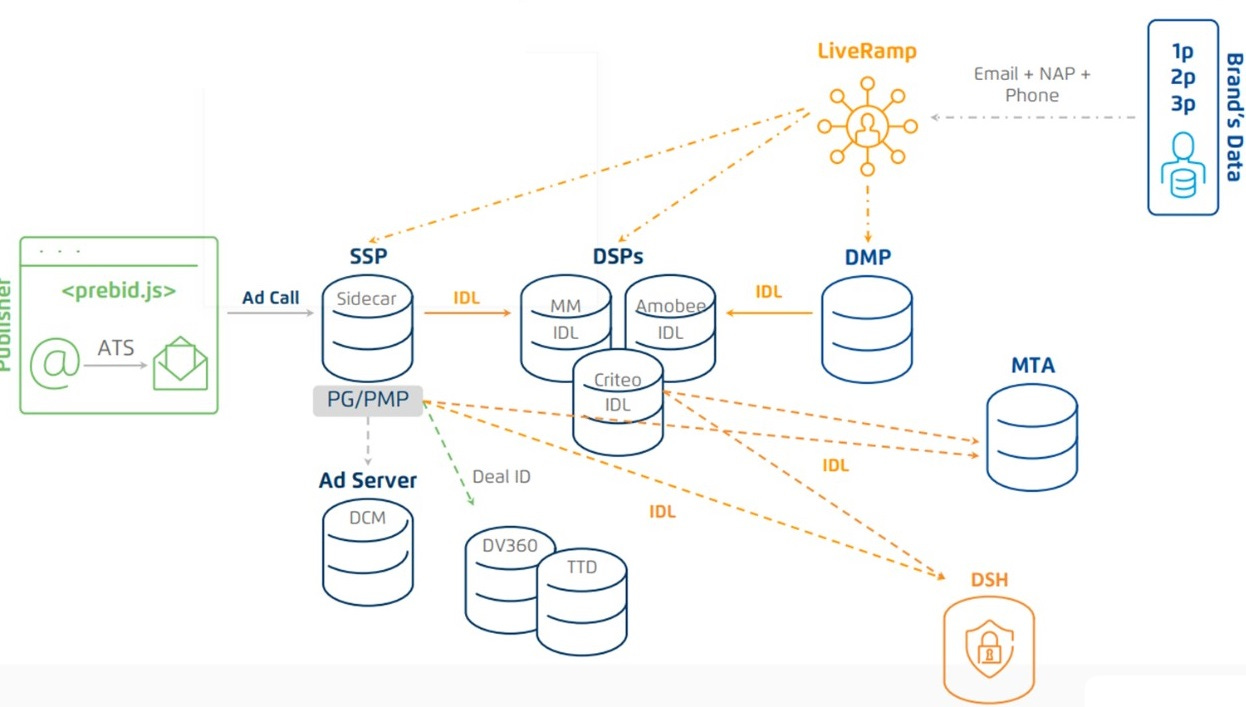
FUENTE: Liveramp, ATS e Identity Link liveramp.com
La medición tiene una premisa sencilla y clara, aunque todavía es un reto que está por conseguir como veremos. Sí todos los interlocutores de una campaña pueden utilizar la tecnología de un Universal ID concreto la identificación en los distintas partes está asegurada y, de ese modo, también la atribución y la medición.
¿Cueces o enriqueces?
Con vuestro permiso saldremos del barro poco a poco y seguiremos un poco más retozando, porque todavía os tengo que hablar de dos piezas fundamentales dentro de cualquier solución “deluxe” de Universal ID que se precie y que en los diagramas no acaban de apreciarse porque están a un nivel más bajo. Me estoy refiriendo a:
Los Identity Graph que se pueden definir como una base de datos que relaciona los identificadores que están asociados con una persona. Estos identificadores incluyen PII y otras identidades digitales y de dispositivos, como correo electrónico, nombre de usuario, número de teléfono, dirección IP, cookies, dirección física, etc. Podemos encontrarlos de dos clases fundamentalmente: los de primera parte que representarían el universo de identidad que tiene una marca y que normalmente encontramos en el CRM, Data Lake, DMP o CDP. Por otro lado, tenemos los de tercera parte que ayudarían a enriquecer (o completar) las identidades de una marca. Por ejemplo, los Walled Garden, Grandes medios, onboarders, etc.
Data Clean Rooms. Si tuviéramos que resumirlo rápido diríamos que es el espacio donde se comparten los datos entre todos los actores involucrados de forma segura y transparente. Normalmente se relacionaban con los espacios de los Walled Garden -Facebook o Google- donde se comparten datos agregados en lugar de datos a nivel individual y se gestionan todos los controles necesarios. Aunque recientemente están experimentando una evolución para ser mucho más transparente con la privacidad de los usuarios (se está avanzando mucho en la integración con Consent Management Platforms) y cumplir la legislación (por ejemplo, GDPR y CCPA), sin necesidad de que las anunciantes y publishers sacrifiquen la atribución y las acciones 1to1 y, que por tanto, son una clara mejora con los Data Clean Rooms de los Walled Garden donde es prácticamente imposibles hacer atribuciones avanzadas o segmentaciones uno a uno.
Pros y contras
Los Universal ID están diseñados para construirse alrededor de varios identificadores que podríamos considerar únicos o deterministas (número de teléfono, dirección de correo electrónico, ID móvil) y, de ese modo, construir la piedra filosofal de la identidad del usuario.
Entonces, la primera pregunta que me surge si esto se basa en crear un identificador universal y único para todos los actores, o los máximos posibles de la industria, es qué empresa u organización se encargará o tendrá el privilegio de llevar a cabo esta misión. Un gran poder conlleva una gran responsabilidad, pero me parece que en este caso habrá varias compañías de la industria AdTech que matarán por conseguir este cometido.
Además, la implementación de esta solución requiere de la identificación de los usuarios a través de un inicio de sesión (login) en el site utilizando un correo o un número de teléfono o de una acción de suscripción a una newsletter. Por ello, esto requiere que se refuercen e impulsen las adopciones de inicio de sesión y captación de 1st Party Data entre anunciantes y medios. Y, en este cometido, justo se está empezando, debido a que los Walled Garden como Facebook, Google y Amazon, llevan siglos de ventaja.
Relacionado también con el volumen, la adopción de las soluciones de Universal ID por los distintos players de la industria todavía no es mayoritaria y, por ende, se deben hacer esfuerzos por llegar a más acuerdos, sobre todo si se quiere competir con los mencionados Walled Garden y otras soluciones cookieless que se están planteando como el Google Privacy Sandbox.
A pesar de los obstáculos comentados, las ventajas son claras, importantes y muy diferenciales en comparación con otras soluciones:
Gran precisión y posibilidad de realizar acciones de targeting 1to1.
Basado en personas, no en dispositivos y/o navegadores. Los modernos lo llamamos people-based.
Gran oportunidad para publishers y anunciantes de cara a mejorar su 1st Party Data.
Transparente para el usuario al trabajar bajo petición de consent (opt-in) transparente.
Está claro que para lograr una solución consistente y duradera en el tiempo, es necesaria una coordinación de toda la industria publicitaria. Sin duda, el Universal ID está bien posicionado para ser esa solución, pero todavía queda mucho trabajo de coordinación y ejercicio de transparencia y consenso con los diferentes agentes AdTech implicados.
Perdón por la extensión 🙏, pero cuando estoy en el barro soy como un niño con botas nuevas en un charco.
Markets are conversations, así que no dudes en participar comentando o compartiendo 📢
Gracias por el ejercicio de síntesis, Antonio. Análisis muy bienvenido. El principal talón de Aquiles que destacaría en el Universal ID es precisamente ese consentimiento que se enarbola como legalmente válido y “transparente”. Adolece del mismo problema que las cookies.
No solo está demostrado que nadie entiende a qué consiente en un CMP (con buenos estudios sobre patrones oscuros en las principales plataformas), sino que las propias agencias de protección de datos de UK y Francia empiezan a cuestionarse que estas cadenas de custodia puedan legitimarse de semejante manera.
La audiencia quiere mucho más control sobre quién les “deduplica” y bajo qué criterios. Y esto solo puede satisfacerse con entornos Walled Garden, lamentablemente, en este momento.
Curiosa encrucijada, porque el más alto estándar de respeto a la privacidad corresponde al listón más bajo en libre competencia.